La entrega de software cambia de verdad cuando el equipo deja de depender de tareas manuales para comprobar, empaquetar y publicar cada cambio. Con integración continua y entrega continua, el foco pasa de “a ver si sale bien” a “qué validaciones me faltan para liberar con confianza”. En proyectos web y de IA esto pesa todavía más, porque las versiones avanzan rápido y cualquier fallo repetido acaba convirtiéndose en retraso, ruido y coste operativo.
Lo esencial que conviene tener claro antes de automatizar el flujo
- CI/CD reduce la fricción entre desarrollo, pruebas, operaciones y negocio.
- La integración continua detecta errores pronto, cuando aún son baratos de corregir.
- La entrega continua deja el software listo para producción, con o sin aprobación manual final.
- La automatización útil no es la más larga, sino la que da señales claras y repetibles.
- En web e IA no solo cuenta el código: también importan tests, configuración y artefactos versionados.
Qué resuelve CI/CD en un equipo real
Yo suelo ver que el valor de CI/CD no está en “modernizar” el equipo, sino en quitar pasos frágiles. Cuando cada cambio pasa por una misma ruta de validación, desaparecen muchos de los problemas que nacen por diferencias entre lo que ocurre en el portátil de un desarrollador, el entorno de pruebas y producción. Eso da algo muy concreto: menos sorpresas.
En la práctica, las ventajas más visibles son estas:
- Feedback rápido, porque el fallo aparece cerca del commit y no tres días después.
- Menos trabajo manual repetitivo, ya que compilar, testear y desplegar deja de depender de pasos “de memoria”.
- Más trazabilidad, porque cada versión se puede relacionar con un cambio concreto en el repositorio.
- Releases más pequeñas, que suelen ser más fáciles de revisar, corregir y revertir.
- Mejor coordinación entre perfiles técnicos y de negocio, porque el estado del software es más visible.
La clave es entender que no automatiza solo para ir más deprisa; automatiza para que el proceso sea más predecible. Y una vez el flujo es predecible, ya merece la pena mirar cómo se construye paso a paso.
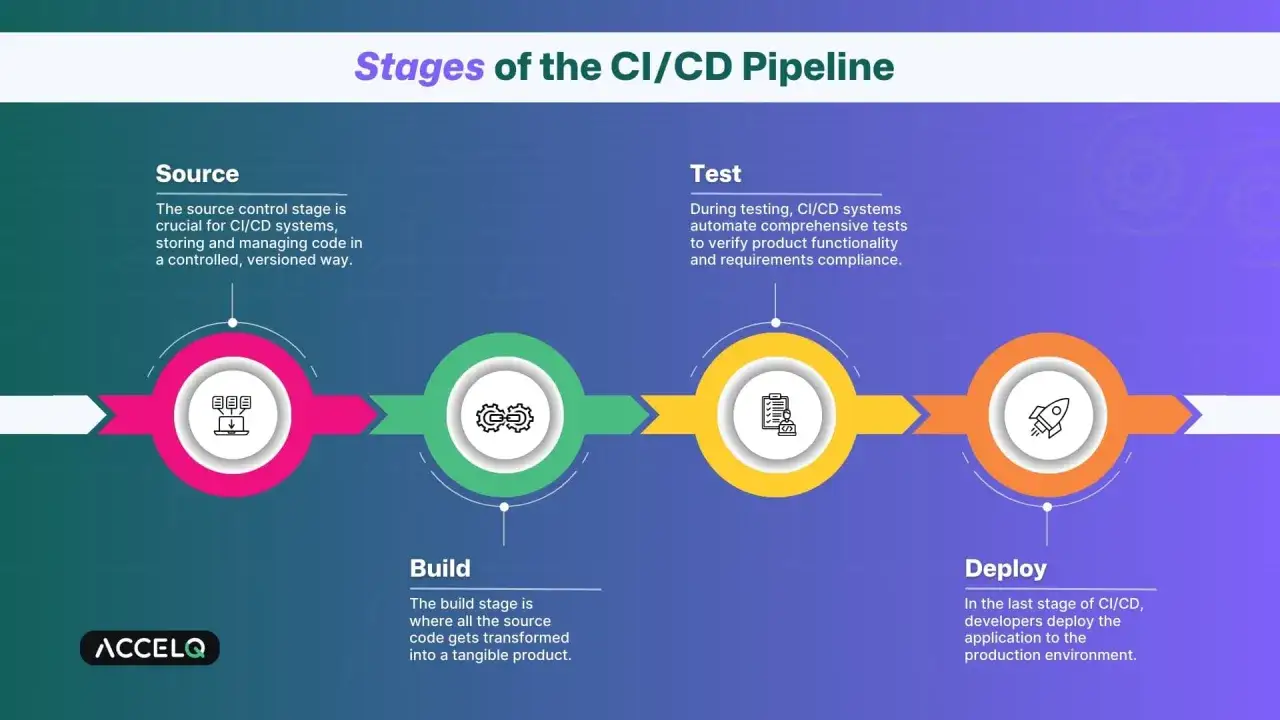
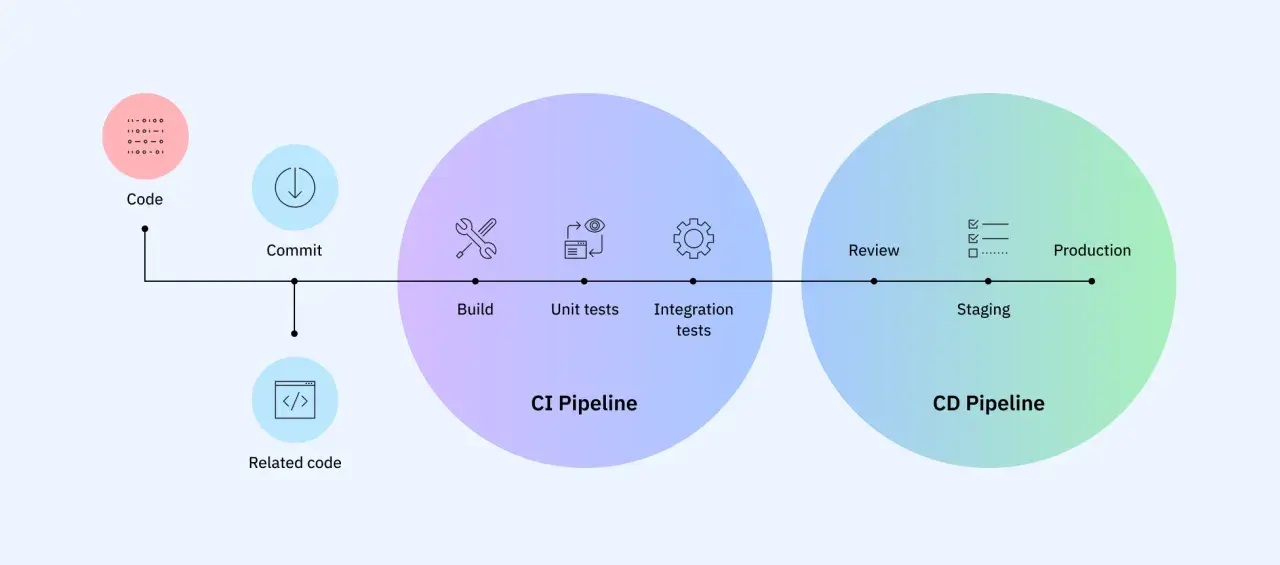
Cómo funciona un pipeline de principio a fin
Un pipeline es una cadena de etapas que se ejecutan cuando hay cambios en el código o en un artefacto del proyecto. En su versión más sensata, empieza con una validación ligera y termina con un entorno donde la aplicación se comporta casi como en producción. Yo prefiero pensar en él como una secuencia de filtros: cada uno elimina una clase de fallo distinta.
1. El commit dispara la validación
Todo empieza cuando alguien hace un push o abre una solicitud de merge. En ese momento el sistema comprueba si el código compila, si las dependencias están bien resueltas y si las reglas básicas del proyecto se respetan. Si esta primera capa falla, no tiene sentido seguir gastando tiempo en pruebas más caras.
2. La compilación o el empaquetado crean el artefacto
En una aplicación web, esto puede significar transpilar JavaScript, construir bundles, generar assets estáticos o crear una imagen de contenedor. La idea es simple: convertir el cambio en algo desplegable y repetible. Si el artefacto cambia en cada ejecución por motivos no controlados, el pipeline deja de ser fiable.
3. Las pruebas automáticas filtran los errores obvios
Aquí entran las pruebas unitarias, de integración y, cuando aportan valor, algunas de extremo a extremo. No hace falta exagerar la cantidad; hace falta que cada tipo de test responda a una pregunta distinta. Las unitarias protegen lógica, las de integración revisan que los módulos hablen bien entre sí y las E2E confirman el recorrido del usuario en escenarios críticos.
4. El entorno de staging valida el comportamiento real
El siguiente paso suele ser un entorno de preproducción que replica lo máximo posible la configuración real. Este punto es especialmente útil cuando hay variables de entorno, colas, bases de datos, APIs externas o permisos que no se comportan igual en local. Si la aplicación pasa aquí, el salto a producción deja de ser una apuesta.
5. La publicación final queda bajo una regla clara
En algunas organizaciones el despliegue a producción se automatiza por completo; en otras se deja una aprobación manual final. Yo no veo ese control humano como un defecto, siempre que sea intencional y no una excusa para mantener procesos opacos. Lo importante es que la decisión esté definida, no improvisada.
Cuando esta secuencia está bien ordenada, el siguiente debate ya no es “¿lo automatizamos o no?”, sino “¿qué parte del proceso conviene automatizar y qué nivel de control queremos conservar?”.
Integración continua, entrega continua y despliegue continuo no son lo mismo
Estas tres ideas se confunden a menudo, pero operativamente no significan lo mismo. Separarlas ayuda a elegir mejor el nivel de riesgo que el equipo está dispuesto a asumir. Si se mezclan, es fácil prometer despliegues automáticos cuando en realidad solo se ha montado una validación de código.
| Práctica | Qué automatiza | Dónde queda el control humano | Cuándo encaja mejor |
|---|---|---|---|
| Integración continua | Compilación, pruebas y verificación tras cada cambio | Antes de llegar a producción, en la revisión del cambio | Cuando quieres detectar errores pronto y mantener la rama principal estable |
| Entrega continua | Preparación automática de versiones listas para liberar | La aprobación final antes de producción puede ser manual | Cuando necesitas control de negocio o validación regulatoria |
| Despliegue continuo | Publicación automática en producción si todo pasa | Muy poco o ninguno | Cuando el sistema de pruebas es sólido y el coste de fallar está muy acotado |
Mi lectura práctica es esta: integración continua es la base, entrega continua es el punto de equilibrio más común y despliegue continuo es una decisión más exigente. No todas las empresas necesitan llegar al último nivel; muchas se benefician muchísimo antes de eso. La siguiente pregunta lógica es con qué herramienta montar esa base sin complicarse de más.
Qué herramientas encajan según el tipo de proyecto
No hay una herramienta “mejor” en abstracto. Hay una herramienta más adecuada para el tipo de repositorio, equipo y cultura de trabajo que ya tienes. Cuando alguien me pregunta cuál elegir, yo miro antes la fricción de mantenimiento que la lista de funciones.
| Escenario | Herramientas que suelen encajar | Por qué tienen sentido |
|---|---|---|
| Equipo pequeño o producto web con repositorio en GitHub | GitHub Actions | Integra bien con el flujo de pull request y reduce piezas adicionales |
| Organización con necesidad de control centralizado | GitLab CI o Azure Pipelines | Facilitan gobernanza, permisos y despliegues por entornos |
| Entornos muy personalizados o heredados | Jenkins | Es flexible, pero exige más disciplina técnica y mantenimiento |
| Flujos de entrega con contenedores y Kubernetes | GitOps con herramientas como Argo CD o Flux | Ayudan a declarar el estado deseado y a desplegar de forma consistente |
Cómo encaja en proyectos web y de IA
En un producto web, el pipeline debería cubrir mucho más que “que compile”. También conviene validar rutas, permisos, estado de la interfaz, accesibilidad básica y tamaños de bundle si el front pesa demasiado. Cuando la web crece, pequeños cambios visuales o de comportamiento pueden romper partes que al equipo le parecen secundarias pero que el usuario nota enseguida.
En proyectos web
Yo suelo recomendar tres capas mínimas: pruebas rápidas de lógica, pruebas de integración para APIs o servicios y una revisión funcional en staging antes de producción. Si además puedes levantar entornos de previsualización por rama, mucho mejor, porque diseño, producto y desarrollo ven el cambio en contexto real sin pelearse con capturas sueltas. Esa visibilidad reduce discusiones y acelera decisiones.
Lee también: Qué es React y por qué lo necesitas - Guía práctica
En proyectos de IA
Con IA la pipeline se vuelve más delicada, porque no basta con comprobar que el código no rompe. También hay que versionar prompts, configuraciones, conjuntos de datos de referencia y, cuando aplica, el propio modelo o sus parámetros. Un cambio mínimo en temperatura, instrucciones o contexto puede alterar bastante el resultado, así que yo añadiría evaluaciones automáticas con casos de prueba representativos y un conjunto de “respuestas esperadas” para detectar regresiones.
La idea importante es esta: en IA, CI/CD no valida solo software, también valida comportamiento. Y si el comportamiento importa, el siguiente paso es evitar los errores que suelen sabotear el proceso desde dentro.
Errores que veo una y otra vez al implantarlo
La mayoría de implantaciones fallidas no se deben a la herramienta, sino al atajo mental con el que se adopta. Estos son los fallos que más se repiten:
- Automatizar un proceso roto, porque si el flujo manual ya era malo, pasarlo a máquina solo acelera el problema.
- Acumular pruebas lentas o inestables, lo que hace que el equipo deje de confiar en la pipeline.
- No proteger la rama principal, dejando que cualquier cambio llegue sin una regla clara de validación.
- Guardar secretos o credenciales mal gestionados, algo especialmente sensible cuando hay varios entornos y proveedores.
- Dejar pasos críticos en manos de conocimiento tribal, es decir, cosas que solo sabe hacer una persona.
Yo añadiría uno más: diseñar el flujo para que parezca sofisticado, no para que sea mantenible. Un pipeline que nadie entiende termina desactivado, y entonces la organización pierde tiempo y confianza a la vez. Para saber si esto está pasando, hace falta medir algo más que “si funciona”.
Qué medir para saber si realmente mejora el trabajo
Si no mides, el debate sobre CI/CD se convierte en opiniones. Y en equipos de desarrollo eso suele ser una pérdida de tiempo. Las métricas útiles no son las más vistosas, sino las que explican si el proceso va más rápido, con menos riesgo y menos retrabajo.
| Métrica | Qué responde | Señal de alerta |
|---|---|---|
| Tiempo de entrega | Cuánto tardas desde el cambio hasta que está listo para usarse | Si un cambio pequeño tarda demasiado, el flujo está sobredimensionado |
| Frecuencia de despliegue | Con qué regularidad publicas cambios | Si desplegar da miedo, seguramente faltan validaciones o claridad operativa |
| Tasa de fallos en cambios | Cuántas liberaciones generan incidentes o revertidos | Si sube, el pipeline no está filtrando bien o el alcance de cada release es demasiado grande |
| Tiempo medio de recuperación | Cuánto tardas en volver a un estado estable tras un problema | Si recuperar cuesta mucho, faltan rollback, observabilidad o disciplina de despliegue |
| Duración del pipeline | Cuánto tarda una ejecución completa | Si el equipo deja de lanzarlo porque “tarda demasiado”, ya no sirve como filtro temprano |
En una conversación con negocio, estas métricas ayudan más que una explicación técnica larga. Traducen la automatización a impacto real: menos esperas, menos incidentes y más previsibilidad. Y con esa base, ya se puede pensar en una implantación sensata, sin sobredimensionar el equipo desde el día uno.
La ruta mínima que yo seguiría para empezar sin sobredimensionar el equipo
Si tuviera que arrancar un flujo serio sin montar una maquinaria innecesaria, empezaría por una sola línea de trabajo bien definida. Primero, protegería la rama principal y dejaría claras las reglas de merge. Después, añadiría compilación y pruebas rápidas en cada cambio, porque ahí suele aparecer la mayor parte de los fallos baratos de corregir.
El tercer paso sería desplegar automáticamente a un entorno de staging lo más parecido posible a producción. El cuarto, dejar una aprobación humana solo donde realmente aporte valor, normalmente antes de producción si el negocio lo necesita. Y el quinto, medir desde el principio para ajustar tiempos, fallos y puntos de fricción. Esa secuencia es bastante más útil que intentar “hacerlo todo” en una sola iteración.
Si una organización web o de IA quiere avanzar con cabeza, yo lo resumiría así: automatiza primero lo repetible, después lo riesgoso y por último lo irreversible. Esa prioridad evita el error más común, que es confundir madurez técnica con cantidad de herramientas, cuando en realidad la madurez se nota en lo bien que el equipo libera cambios sin perder control.