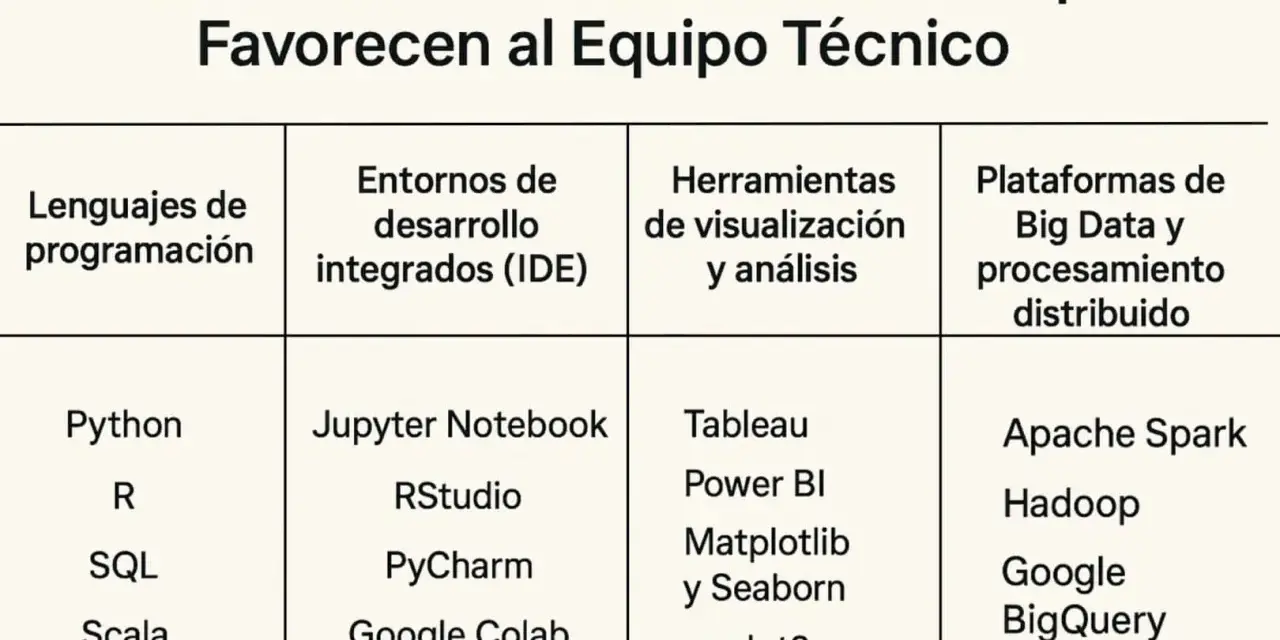
Analizar datos masivos no consiste en acumular nombres de software, sino en elegir bien cada capa de trabajo: ingestión, almacenamiento, procesamiento, visualización y control. Cuando esa combinación encaja, el equipo gana velocidad, reduce costes y evita rehacer flujos cada pocos meses. En este artículo explico qué hace cada tipo de herramienta, cuáles tienen más sentido hoy y cómo decidir una arquitectura realista según el tamaño del proyecto, el presupuesto y el nivel técnico del equipo.
Cada capa del dato pide una herramienta distinta
- Las plataformas de datos no sustituyen a SQL, Python ni al modelado; los hacen más potentes.
- Kafka, Spark, BigQuery, Databricks y Power BI resuelven problemas diferentes y no compiten en el mismo nivel.
- En 2026 gana peso la arquitectura lakehouse y la nube, pero solo si encajan con el caso de uso y con el equipo.
- Si el dato llega en tiempo real, la pila cambia; si el objetivo es reporting, puede ser mucho más simple.
- La mejor elección suele ser la que reduce fricción operativa, no la que más ruido genera.
Qué problema resuelven estas plataformas
Cuando hablo de big data, pienso en proyectos donde el problema ya no es solo guardar información, sino moverla, limpiarla, cruzarla y convertirla en decisiones útiles. En ese escenario, una base de datos clásica o una hoja de cálculo se quedan cortas porque no pueden sostener el volumen, la velocidad o la variedad de los datos sin perder agilidad.
Yo suelo separar la necesidad en cinco preguntas simples: ¿de dónde llega el dato?, ¿dónde se guarda?, ¿quién lo procesa?, ¿quién lo consume? y ¿quién controla que sea fiable? Si respondes bien a esas cinco cuestiones, la elección de software deja de ser una lista de marcas y pasa a ser una arquitectura con sentido.
- Volumen: cuando hay demasiados registros para trabajar con herramientas tradicionales.
- Velocidad: cuando el dato llega continuamente y no puedes esperar al cierre del día.
- Variedad: cuando conviven tablas, logs, texto, imágenes o eventos de aplicaciones.
Por eso, no me interesa tanto la herramienta aislada como la combinación de varias capas que funcione sin fricción. Con esa base, ya tiene sentido mirar la arquitectura de forma ordenada.
Cómo se reparte el trabajo en una arquitectura de datos
Ingesta. Aquí entran herramientas como Apache Kafka o sus conectores. Su función no es analizar, sino transportar eventos de forma fiable para que el resto del sistema reciba el dato sin depender de integraciones frágiles entre aplicaciones.
Almacenamiento. En este nivel aparecen BigQuery, Snowflake o entornos lakehouse como Databricks. Un lakehouse combina la flexibilidad de un data lake con la estructura de un data warehouse, y eso lo hace útil cuando necesitas analizar mucho dato sin renunciar a orden y gobierno.
Procesamiento. Apache Spark y PySpark siguen siendo referencia cuando el cálculo tiene que escalar. Spark trabaja de forma distribuida y sirve tanto para lotes como para streaming, así que yo lo veo como una pieza muy sólida cuando el dato ya no cabe en una sola máquina o cuando hay transformaciones complejas.
Consumo. Power BI entra aquí con mucha fuerza en entornos empresariales porque convierte modelos y métricas en informes comprensibles. No sustituye la capa de datos, pero sí hace que el negocio vea el resultado sin pelearse con tablas crudas.
Gobernanza. Aquí entran el catálogo, los permisos y el linaje. El linaje es el rastro que muestra de dónde sale cada dato y qué transformaciones ha sufrido; sin eso, auditar o corregir errores se vuelve lento y caro.
Cuando se entiende esta secuencia, comparar herramientas deja de ser una cuestión de reputación y pasa a ser una decisión técnica con impacto real.
Las opciones que más sentido tienen en 2026
No pondría todas las herramientas en la misma bolsa. Yo las comparo por función, por curva de aprendizaje y por coste operativo, porque el error más caro es comprar una pieza potente para un problema sencillo.
| Capa | Herramientas habituales | Para qué las usaría | Coste habitual | Límite principal |
|---|---|---|---|---|
| Ingesta y streaming | Kafka, Kafka Connect | Mover eventos y datos en tiempo real entre sistemas | Licencia 0 €, infraestructura y operación aparte | No analiza por sí solo |
| Procesamiento distribuido | Spark, PySpark | Transformación masiva, batch, streaming y ML | Licencia 0 €, cómputo y tuning aparte | Puede complicarse si se usa para todo |
| Almacenamiento y SQL cloud | BigQuery, Snowflake | Consultar grandes volúmenes sin gestionar tanta infraestructura | Pago por consumo, consultas y almacenamiento | Hay que vigilar el uso para no disparar costes |
| Lakehouse | Databricks | Unir ingeniería, analítica y ML en una misma base | Consumo cloud por cómputo y almacenamiento | Puede sobredimensionarse en proyectos simples |
| BI y reporting | Power BI | Cuadros de mando, autoservicio y distribución de métricas | Licencia por usuario o capacidad | No sustituye la capa de datos |
| Programación y análisis | SQL, Python | Exploración, limpieza, automatización y modelos | Licencia 0 €, coste en tiempo y entorno | No escala sola sin motor detrás |
Hay una regla que yo uso mucho: en open source la licencia puede costar 0 €, pero la operación nunca es gratis; en cloud, el gasto se desplaza a consumo, almacenamiento, consultas y licencias por usuario. Esa diferencia es importante porque cambia el coste total de propiedad, no solo el precio de entrada.
También conviene decirlo sin rodeos: Hadoop sigue apareciendo en entornos heredados, pero para un proyecto nuevo yo compararía antes Spark, BigQuery, Snowflake o Databricks. La conversación técnica ha evolucionado hacia arquitecturas más flexibles y menos pesadas de mantener.
La pregunta, entonces, no es qué herramienta está de moda, sino cuál te deja trabajar con menos fricción.
Cómo elegir según tamaño, presupuesto y equipo
Si me toca orientar un proyecto desde cero, empiezo por el uso real, no por el catálogo.
- Si el objetivo es reporting y control de negocio, uso SQL, una plataforma cloud gestionada y Power BI.
- Si hay batch pesado, transformación compleja o ML, me apoyo en Spark o en un entorno lakehouse como Databricks.
- Si el dato llega por eventos o sensores, Kafka entra antes que cualquier dashboard.
- Si el equipo es pequeño, priorizo herramientas gestionadas antes que montar clústeres propios.
- Si hay datos personales o requisitos RGPD, la gobernanza, los permisos y el linaje pesan tanto como la velocidad.
Yo no empezaría con una arquitectura en tiempo real si el negocio solo necesita informes diarios, ni con una plataforma muy compleja si el equipo apenas domina SQL. En España, en muchas pymes, una combinación sobria suele rendir mejor que una pila muy ambiciosa que luego nadie mantiene.
Esa sobriedad también ayuda a aprovechar mejor la IA, que hoy se ha convertido en una capa adicional, no en un sustituto de la arquitectura.
Qué cambia cuando entra la IA en el flujo de trabajo
La IA está cambiando la forma de explorar datos, pero no elimina el trabajo duro. Cada vez veo más asistentes que generan consultas, resumen dashboards, detectan anomalías o ayudan a buscar métricas con lenguaje natural; son útiles para acelerar el arranque y para equipos mixtos que no tienen un perfil técnico profundo en cada mesa.
El límite está claro: un copiloto puede sugerir una consulta correcta y, aun así, devolver una respuesta engañosa si el modelo semántico está mal definido, si los KPI no están cerrados o si los permisos están mal configurados. Dicho de otra forma, la IA mejora la interfaz con el dato, pero no arregla una mala definición de negocio.
- Sí aporta: exploración más rápida, automatización de tareas repetitivas, documentación y apoyo al autoservicio.
- No sustituye: gobernanza, calidad del dato, diseño de métricas ni criterio analítico.
Por eso, cuando una plataforma presume de IA, yo miro antes su base de datos, sus permisos y su trazabilidad que el asistente que enseña en la demo. Eso me lleva a los fallos más comunes, que casi siempre están antes de la tecnología.
Los errores que encarecen el proyecto
La mayoría de los proyectos no fracasa por falta de potencia, sino por decisiones mal encajadas al principio. Yo suelo ver estos errores una y otra vez:
- Confundir BI con plataforma de datos. Un dashboard no arregla tablas mal modeladas ni datos sucios.
- Montar tiempo real sin necesidad real. Subir la complejidad porque sí suele encarecer soporte, monitorización y seguridad.
- Elegir por moda. La herramienta más comentada no es necesariamente la que mejor encaja con el equipo.
- No medir el coste de uso. En la nube, unas pocas consultas mal diseñadas pueden disparar el gasto.
- Dejar la calidad para el final. Cuando la limpieza y el linaje llegan tarde, casi siempre hay que rehacer trabajo.
- Ignorar la operación diaria. Una pila que no puede mantenerse con el equipo real acaba abandonada.
Si evitas estos tropiezos, la tecnología deja de ser una fuente de fricción y se convierte en una palanca de negocio. A partir de ahí ya tiene sentido pensar qué base mínima conviene aprender o implantar primero.
La combinación mínima que yo aprendería primero
La combinación mínima que yo aprendería primero es bastante simple: SQL para consultar, Python para automatizar, Power BI para comunicar y una plataforma cloud gestionada para escalar cuando haga falta. A esa base añadiría Spark o un lakehouse solo cuando el volumen o la complejidad lo pidan de verdad, y Kafka únicamente si el tiempo real es parte del problema.
- Para estudiantes de FP, esta secuencia da criterio técnico sin dispersarse en diez herramientas a la vez.
- Para profesionales de gestión, ayuda a entender qué pedir, cuánto cuesta y dónde están los riesgos.
- Para empresas pequeñas y medianas, evita sobredimensionar la arquitectura antes de tener valor claro.
Si tuviera que resumirlo en una idea práctica, diría esto: empieza por la menor pila que resuelva bien el problema y solo añade capas cuando el dato lo justifique. Esa disciplina ahorra tiempo, dinero y rehacer trabajo, que al final es lo que más pesa en cualquier proyecto serio.